Breaking Through Tabular Constraints for Synthetic Data Generation
— Most synthetic data generation tools assume flat tables. Real-world application data is often nested JSON with optional fields and variable-length arrays. The ORiGAMi architecture handles semi-structured data directly.
Teams need realistic data for testing, development environments, database optimization and ML training, but without exposing actual user records. For simple tabular data, there are decent tools and algorithms to generate synthetic records, spanning various architecture families: GANs and VAEs, diffusion models, and more recently LLMs. But if your data has nested objects, optional fields, or variable-length arrays (typical application layer data and API payloads), the usual workaround is to flatten everything into tables during preprocessing. This creates wide sparse tables and turns nested structure and array lengths into column-layout artifacts.
In our recent paper, we study how existing synthesizers hold up when applied to flattened semi-structured data, and introduce a new model architecture that sidesteps the problem entirely. ORiGAMi (Object Representation via Generative Autoregressive Modelling) is a modified transformer that operates on JSON directly — no flattening required. It learns structure, sparsity patterns, and statistical relationships directly from the raw JSON records.
Application data looks different
Here’s a simplified business listing from Yelp:
{
"name": "Joe's Pizza",
"stars": 4.5,
"is_open": true,
"categories": ["Pizza", "Italian", "Restaurants"],
"hours": {
"Monday": "11:00-22:00",
...
"Sunday": "11:00-23:00"
},
"attributes": {
"WiFi": "free",
"OutdoorSeating": true,
"NoiseLevel": "average",
...
},
...
}
Nested objects, variable-length arrays, keys that show up in some records but not others. If you’ve worked with document databases, REST APIs, or event streams, this is familiar. It’s how most application-layer data is shaped.
To use a tabular synthesizer on data like this, you first have to flatten it into a table. categories becomes categories.0, categories.1, categories.2, one column per array slot. hours.Monday and attributes.WiFi become top-level columns. Records missing a key get a blank cell. The resulting representation is wide, sparse, and awkward for many ML algorithms.
We flattened the 150,000-record Yelp business listings dataset this way. The result was a table with 142 columns and 78% empty cells.
The problem with mixed types
Even on flat tables, there’s a fundamental tension in how synthesizers handle different data types. GAN, VAE, and diffusion-based methods work in continuous space, so they handle numbers naturally but need to encode categories as one-hot vectors. That’s fine for a column with 5 distinct values, but falls apart when you have thousands of distinct categories. Flattened semi-structured data makes this worse: array expansion turns a single categories field into dozens of columns, each with its own set of repeating values.
Autoregressive and LLM-based methods have the opposite problem. They treat everything as tokens, so categories are easy. But numeric values with high precision (prices, coordinates, timestamps) would need enormous vocabularies to represent exactly, so they get discretized into bins, losing precision and ordinal structure in the process.
Both camps compromise. ORiGAMi sidesteps this by using a dual-head architecture: one head predicts discrete tokens (keys, categories, structural markers), and a separate head models high-precision numeric values as continuous distributions. Each data type stays in its native representation.
What breaks with sparsity
We benchmarked synthesizers from all the major architecture families on six datasets, ranging from standard dense benchmarks to large-scale JSON collections. As the data gets less tabular and sparser, three things go wrong.
First, many methods simply can’t run. TVAE and CTGAN one-hot encode categorical values — each unique value becomes its own column. On Yelp, the flattened representation contains roughly 27,000 discrete values, and these models cannot fit in memory. GReaT and Tabby, the language model-based variants, default to GPT-2 under the hood, which has a 1,024-token context window. Flattened Yelp records need around 2,900 tokens with standard sub-word tokenizers. On our largest dataset (1.16 million medical records), only two of six baselines could even start training on a single V100 GPU with 16GB of memory.
Second, imputation corrupts sparse columns. The standard approach to fill missing numeric values is to replace them with the column mean. But if 95% of a column’s values are missing, the model learns a distribution dominated by that artificial spike rather than the actual data. A classifier trained to detect synthetic data picks this up immediately.
Third, discretizing continuous values into bins introduces its own artifacts. In one case, a single bin spanned 71,000 units, and a few clustered outliers got smeared into a uniform distribution. Again, trivial to detect.
Working with the structure
The ORiGAMi architecture is designed to skip flattening altogether. It reads JSON records directly and generates JSON records directly. A few things make this work.
Each record is tokenized into a sequence of keys, values, and structural markers (things like “object starts here” or “array ends here”). Nesting and optional keys are just part of the sequence, so there’s nothing to flatten or pad. These sequences are trained with transformers, the same architecture family powering modern LLMs.
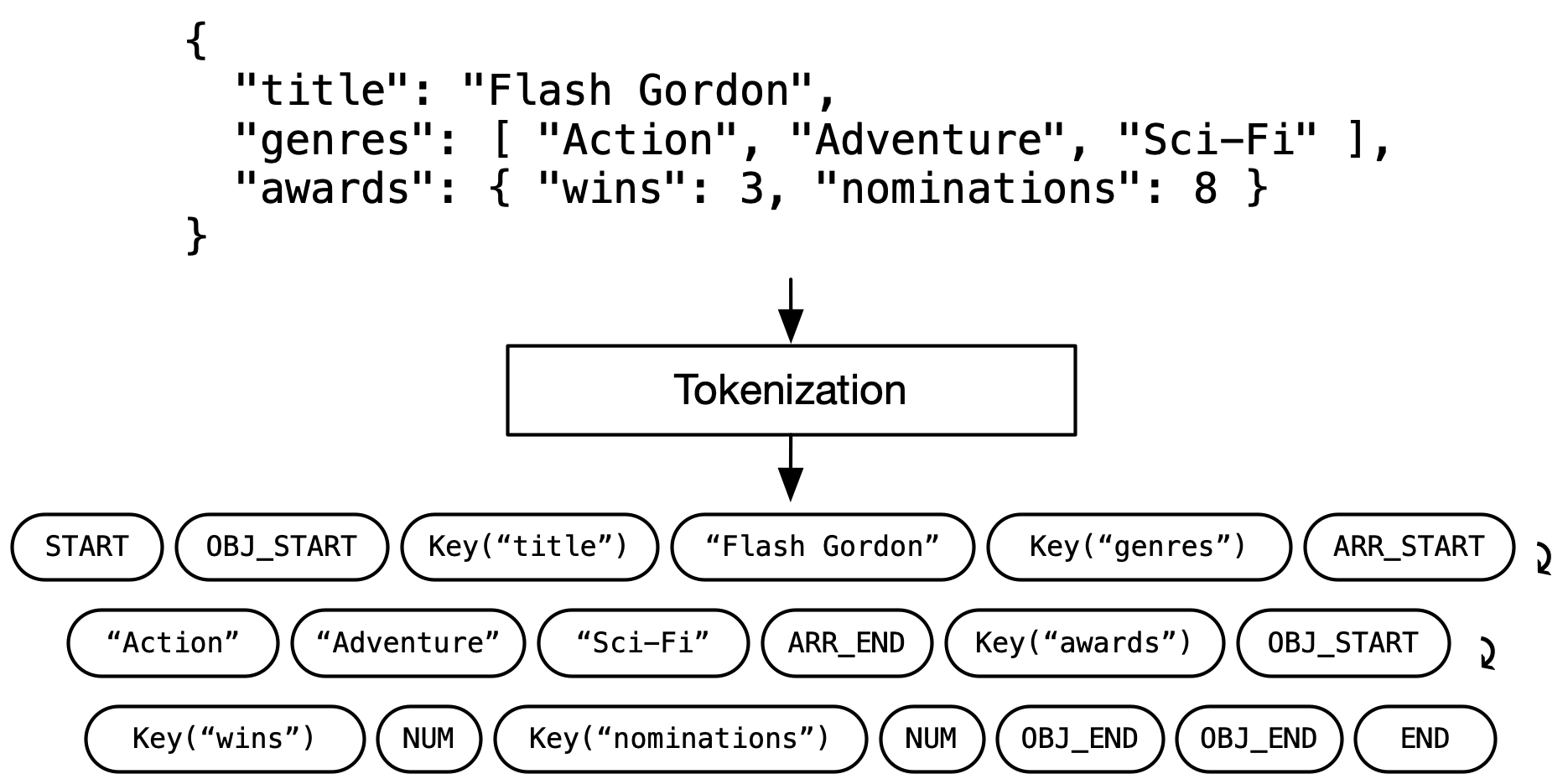
The trickier problem is position encoding. Language models usually number their tokens sequentially: in simple terms, they see tokens in order, token 1, token 2, and so on. But in JSON, {"name": "Alice", "age": 30} and {"age": 30, "name": "Alice"} are the same record. And for data with missing keys, the absolute position of the age token may be different across records. So instead of sequential positions, ORiGAMi encodes each token’s path through the document tree. The value 30 gets tagged as “the value at the age position,” not “the fifth token.” We call this Key-Value Position Encoding (KVPE), and it’s what lets the model tell apart identically named fields at different locations, user.name versus company.name, for instance.
ORiGAMi handles high-cardinality numbers as continuous values by predicting the parameters of a Gaussian mixture distribution. Categories and strings go through a standard token prediction head. Both work in their native representation.
To make sure every generated record is actually valid JSON, a pushdown automaton tracks the grammar state during generation. At each step, any token that would break the syntax gets masked out. A second layer of constraints, compiled from the training data’s schema, restricts which keys can appear and what values are legal for each key. The output is guaranteed to be valid, well-typed JSON. Not because of post-processing, but because the model literally cannot produce anything else.
Results
We evaluated on six datasets with increasing complexity: Adult and Diabetes (standard dense benchmarks, 49K and 81K records respectively), Electric Vehicles (210K records, 11% sparsity), Yelp (150K records, 78% sparsity), GitHub Issues (642K records, 93% sparsity) and DDXPlus (1.16M records, 67% sparsity).
The first thing to look at is which methods could run at all:
| Tabby | TVAE | CTGAN | REaLTabFormer | TabularARGN | TabDiff | ORiGAMi | |
|---|---|---|---|---|---|---|---|
| Adult | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Diabetes | OOM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Electric | OOM | OOM | OOM | ✓ | ✓ | ✓ | ✓ |
| Yelp | OOM | OOM | OOM | ✓ | ✓ | ✓ | ✓ |
| GitHub Issues | OOM | OOM | OOM | OOM | ✓ | ✓ | ✓ |
| DDXPlus | OOM | OOM | OOM | OOM | ✓ | ✓ | ✓ |
By the third dataset, half the baselines are out of memory (OOM).
For the methods that did run, we measured how hard it is for an XGBoost classifier to tell real records apart from generated ones. A score of 1.0 means the classifier performs no better than random guessing, i.e., the synthetic data is indistinguishable from real. A score of 0.0 means it separates them trivially.
On the dense benchmarks (Adult and Diabetes), detection scores among top performers are high and closely bunched. But despite being designed for semi-structured data, ORiGAMi outperforms all competitors even here. TVAE and CTGAN are easily detected on the datasets where they can run. As sparsity increases, the differences become more visible: TabDiff and TabularARGN both degrade on Yelp and DDXPlus, while ORiGAMi remains hardest to distinguish from real data on every dataset. The GitHub Issues dataset is the closest case, with ORiGAMi only slightly ahead of TabularARGN.
Fidelity and utility scores tell a similar story, though with smaller margins. ORiGAMi has the highest fidelity on all six datasets and the best or tied-best ML utility on five of six (REaLTabFormer edges it out on Yelp). Details are in the paper.
Worth noting: ORiGAMi is also the smallest model. For the Yelp dataset, it has 1.7M parameters, 5x smaller than TabularARGN (9M) and 35x smaller than REaLTabFormer (59M).
What the metrics miss
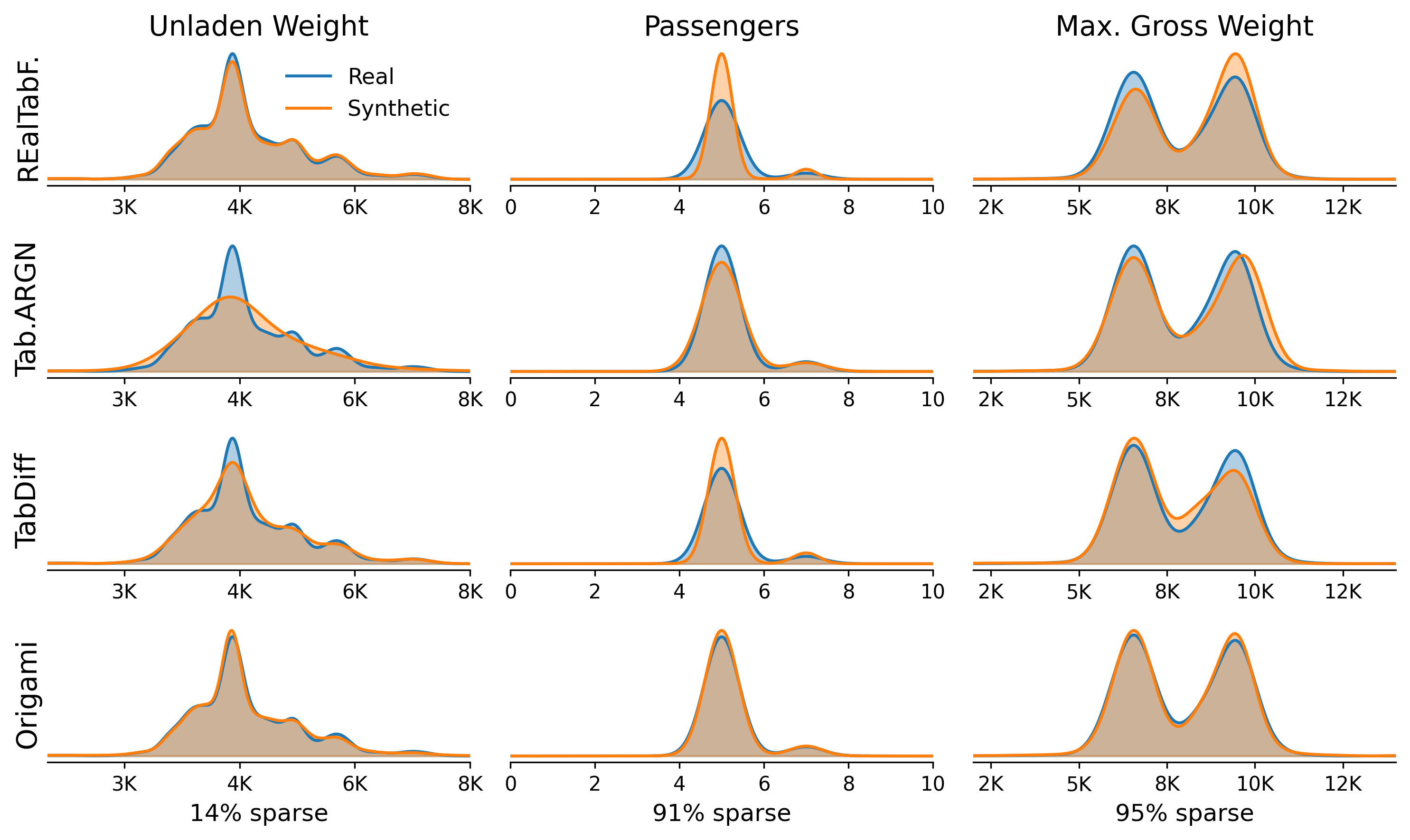
But where does it actually break down? The evaluation metrics don’t tell the full story. We looked at the raw density distributions of the numeric columns for Electric Vehicles — with only 11% sparsity, one of the easier datasets. Even here, the artifacts are visible. TabDiff’s distributions are dominated by the imputed column mean, distorting the true distributions. TabularARGN and REaLTabFormer show discretization artifacts where continuous values have been binned, e.g., a smoothed-out curve for TabularARGN’s Unladen Weight column due to its uniform intra-bin sampling approach. ORiGAMi’s distributions follow the real data closely.
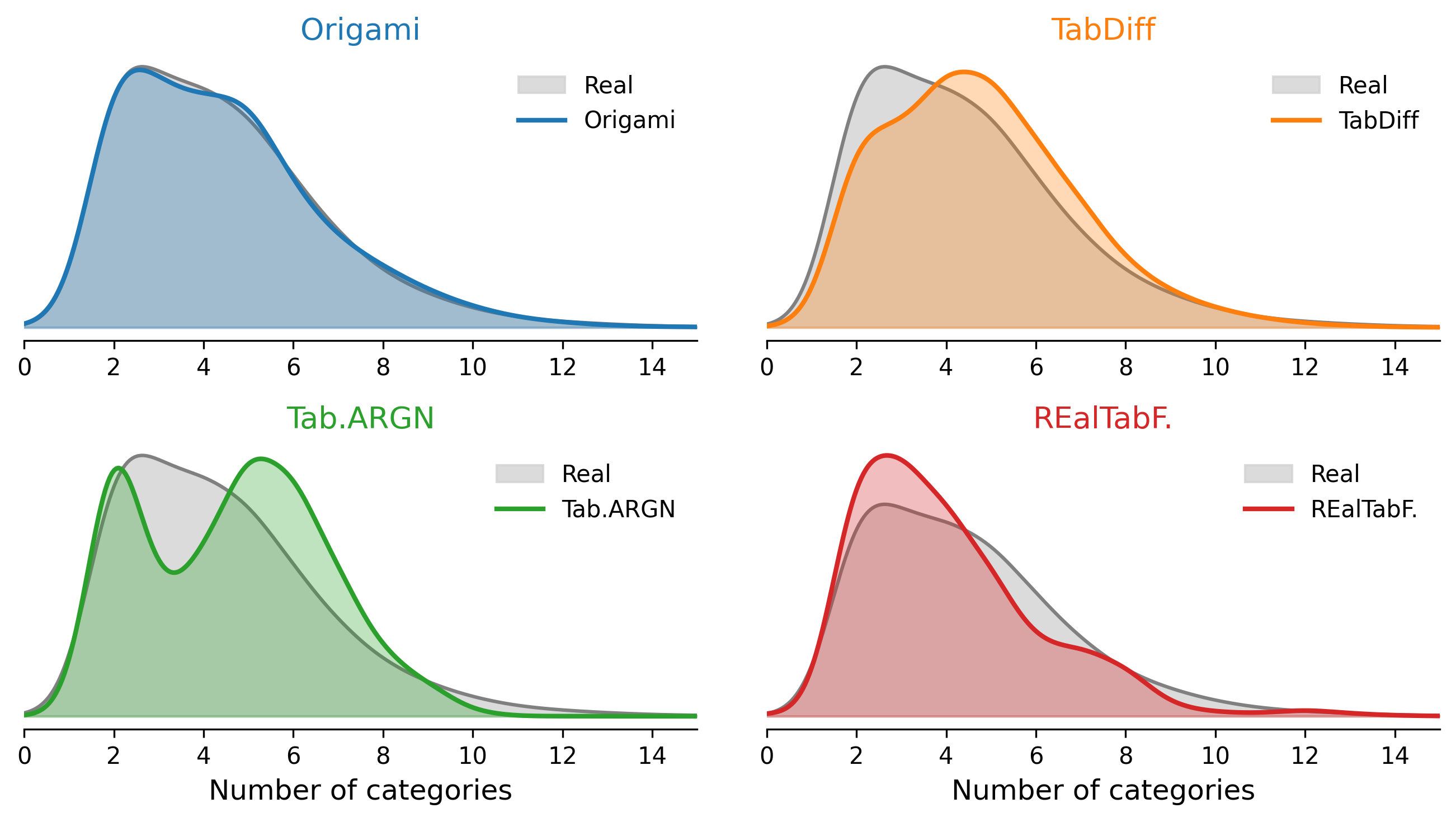
Arrays expose a different failure mode. When a variable-length array is flattened into categories.0, categories.1, categories.2, and so on, the number of non-null entries in those columns determines the implied array length. The length is implicit rather than a directly modeled quantity. ORiGAMi, operating on JSON sequences directly, learns the length distribution as part of the sequence model. The difference is visible in the Yelp categories array: REaLTabFormer has a strong outlier at length 2, and TabularARGN and TabDiff overshoot toward longer arrays. ORiGAMi’s array length distribution matches the real data most closely.
Beyond Synthetic Data Generation
Because ORiGAMi is an autoregressive model, it’s also a density estimator. It assigns a probability to every record it sees. Generating synthetic data is just one thing you can do with that. Conditioning on a partial record and sampling the rest gives you data imputation and predictive modeling without needing a separate model. Scoring records by their log-likelihood gives you outlier detection for free. For database workloads specifically, the same architecture could be used for learned cardinality estimation on semi-structured data, a key component of query optimization in databases. We’ll explore these capabilities in future work.
The paper preprint is available on arXiv and the code is on GitHub. ORiGAMi is additionally published as a Python package (origami-ml) with a Python SDK and CLI.
Thomas Rückstieß is the founder of Relaxed Constraints and former head of ML Research at MongoDB. This work was done in collaboration with Robin Vujanic, Staff Research Scientist at MongoDB.